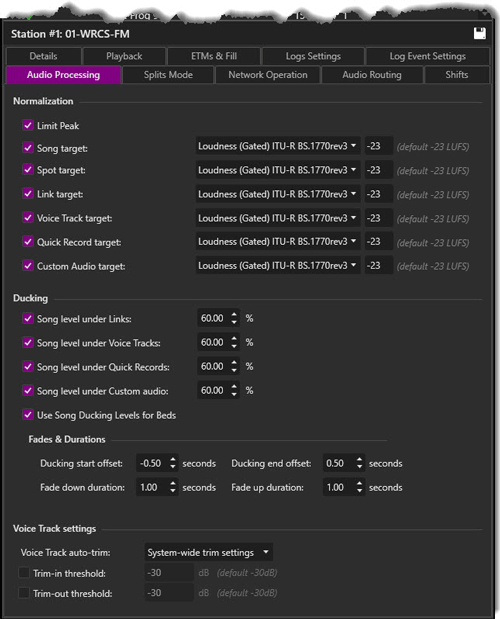
Welcome < Configuration < Stations < Audio Processing
The Audio Processing tab is used to set the Normalization, Ducking and Voice Track settings for each station.
See also the Audio Processing and Normalization topic in the Features section for more information on how Audio is processed in Zetta.
Click any area in this image for help
Click any area in this image for help
In this Topic: show/hideshow/hide
Loudness (EBU R128) ITU-R BS.1770rev0
Loudness (Gated) ITU-R BS.1770rev3
Song Level Under Quick Recording
Normalization is the process of increasing (or decreasing) the amplitude of an entire audio signal so that the resulting peak amplitude matches a desired target. Zetta® has the ability to use a RCS® Direct Show Peak form filter to calculate Peak form value, Trim in/out, Segue and run normalization analysis. These normalization values are also used in Zetta2GO. See the Audio Processing and Normalization topic in the Features section for more information on how Audio is processed in Zetta. The following Normalization Algorithms are supported by Zetta.
Loudness (EBU R128) ITU-R BS.1770rev0
Loudness (Gated) ITU-R BS.1770rev3
When the Limit Peak option is check the Absolute Peak will default at -20dB
Absolute peak (As used in AFC 4.0) normalization checks every sample in the audio file and calculates the largest audio peak value.
Root Mean Square (As used in Selector/MC 15) normalization uses the square root mean algorithm to calculate peak values, which is the square root of the mean or middle of the squares of the values.
Filtered Peak (As used in AFC 3.0) normalization analyzes all the samples within an audio file and calculates the peak level by ignoring 5% of highest samples.
Average peak normalization is new with Zetta®; it analyzes all the samples within an audio file and calculates the median or middle value of the top 5% of the peaks.
Loudness normalization is concerned with balancing audio according to their actually perceived loudness. The EBU R128 is the recommended level of loudness at -23LUFS. The ITU-R BS.1770 standards provide an algorithm for quantifying the loudness and loudness level of a given audio asset in loudness units (LU or LUFS). To have the system adjust the playback level of the mono audio files, use the Mono files Pan law compensation setting in the global Audio Processing tab of the System Configuration window.
Loudness (Gated) ITU-R BS.1770rev3 is an algorithm to measure audio loudness of a Gated block of audio. This is the default setting and is recommended for Broadcast audio. To have the system adjust the playback level of the mono audio files, use the Mono files Pan law compensation setting in the global Audio Processing tab of the System Configuration window.
Ducking allows the user to setup ducking percentages, duration and Fade time for ducking Songs under Links, Voice Tracks, Quick Record and Custom audio types. Ducking allows the playout device to temporarily reduce the volume of a currently playing element (typically a song) when another element plays on top of it (so that they don't "fight" for on-air presence). Good examples could be a jingle auto posted over song's Intro, or Voice Tracks overlapping the ending of the previous song and the opening of the next song.
The Song Level Under Links is the percentage amount to reduce the audio level of the song when played at the same time as a Link. The lower the value the more Zetta will reduce the volume. (Default is 60%) When a Link is set as a Bed the audio level of the song will not be reduced. The Ducking for a Song to Link is from Trim In to Segue of the Link.
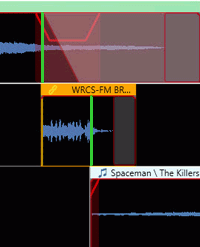
The Song Level Under Voice Tracks is the percentage amount to reduce the audio level of the song when played at the same time as a Voice Track. The lower the value the more Zetta will reduce the volume. (Default is 60%) When a Voice Track is set as a Bed the audio level of the song will not be reduced. The Ducking for a Song to Voice Track is from Trim In to Trim Out of the Voice Track.
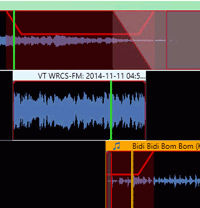
The Song Level Under Quick Recording is the percentage amount to reduce the audio level of the song when played at the same time as a Quick Recording. The lower the value the more Zetta will reduce the volume. (Default is 60%) When a Quick Recording is set as a Bed the audio level of the song will not be reduced. The Ducking for a Song to Quick Record is from Trim In to Trim Out of the Quick Record.
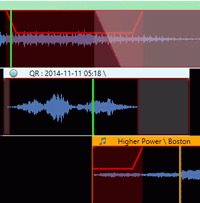
The Song Level Under Custom Audio events is the percentage amount to reduce the audio level of the song when played at the same time as a custom asset type. The lower the value the more Zetta will reduce the volume. (Default is 60%). For additional information on custom asset types see the Asset Types tab in the System Configuration and the Custom Asset Type Tabs section in the Library topic of this guide. When a Custom Asset Type is set as a Bed the audio level of the song will not be reduced. The Ducking for a Song to Custom Asset Type is from Trim In to Segue of the custom asset.
When an asset such as a Link is marked as a Bed, Zetta will use the Song Ducking Level for the bed. When the above options are used for Song Level and this option is also used, the bed will be ducked under the asset. For example: If the option Song Level Under Links is selected, the bed is ducked whenever a link overlaps the bed.
Ducking Start Offset in Seconds – The Ducking Start Offset is the amount of time to start fading down the song before the link or voice track audio begins. If the value is negative, ducking starts first, followed by a Link/VT (the value controls how much time ahead the ducking starts). If the value is positive, the Link/VT starts first, followed by an actual ducking (the value controls how much time into the link/VT the ducking starts)
Ducking End Offset in Seconds – The Ducking End Offset is the amount of time to fade up the song before the link or voice track audio ends. If the value is negative, fade up will be completed before a Link/VT end (the value controls how much time before the link/VT finishes that the song will need to be at full volume). If the value is positive, fade up will be completed after a link/VT end (the value controls how much time after the link/VT finishes that the song will need to be at full volume).
Fade Down Duration in Seconds – The Fade Down Duration is the time to start fading the song down to the target volume, at the Ducking Start Offset.
Fade Up Duration in Seconds – The Fade Up Duration is the time to start fading the audio back up to the original volume, at the Ducking End Offset.
The Voice Track settings in the Station Audio Processing tab are used to override the system Voice Track settings that are set in the Configuration | System | Audio Processing tab. When Multisite Voice Tracking is used, if only one station is selected to be Voice Tracked, MVT will use that station's settings, otherwise, the system settings are used for all selected stations.
Voice Track auto-trim - The Voice Track auto-trim drop-down is used to select on of the following three options:
Trim-in threshold – Trim-in is an open marker to define where “silence” ends and actual audio begins. (Default -30dB)
Trim-out threshold – Trim-out is a closing marker where audio becomes “silence”. (Default -30dB)
|
Important Note! |
If the Station-specific trim settings is selected from the Voice Track auto-trim drop-down but the Trim-in and Trim-out threshold are unchecked, this is in essence like choosing Disabled. |
Welcome < Configuration < Stations < Audio Processing
© 2007-2024 RCS All Rights Reserved.
